Hi Itay,
I think something in the PQL formula(s) is causing the duplication/increase. Not sure what it is but I would suggest searching there!
One thought is your result set greater than 1000 rows? If so, by sorting you are getting only the largest 1000 data points skewing upward rather than averaging an unsorted set.
Hi Itay,
I think something in the PQL formula(s) is causing the duplication/increase. Not sure what it is but I would suggest searching there!
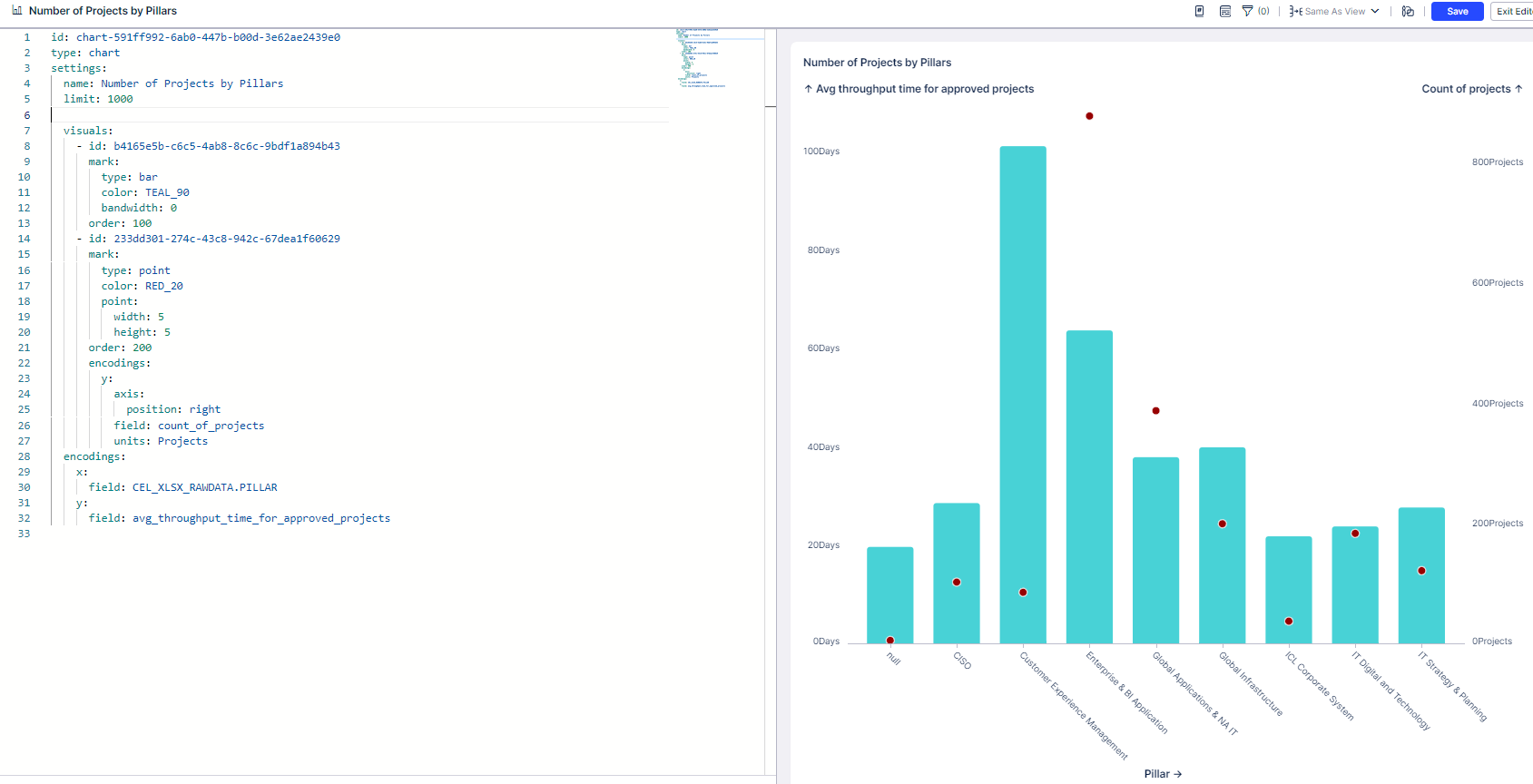
Bar -
X axis PQL:
"_Cel_Xlsx_RawData"."Pillar"
Y axis PQL:
AVG( CALC_THROUGHPUT (
FIRST_OCCURRENCE C'Pending Idea'] TO LAST_OCCURRENCE C'Approved'] ,
REMAP_TIMESTAMPS ( "_CEL_XLSX_ACTIVITIES"."Date" , DAYS,
WEEKDAY_CALENDAR ( SUNDAY MONDAY THURSDAY WEDNESDAY THURSDAY) ) ) )
Point-
Y axis PQL:
COUNT ( "_CEL_XLSX_RawData"."JOINED ID" ) ---count of projects.
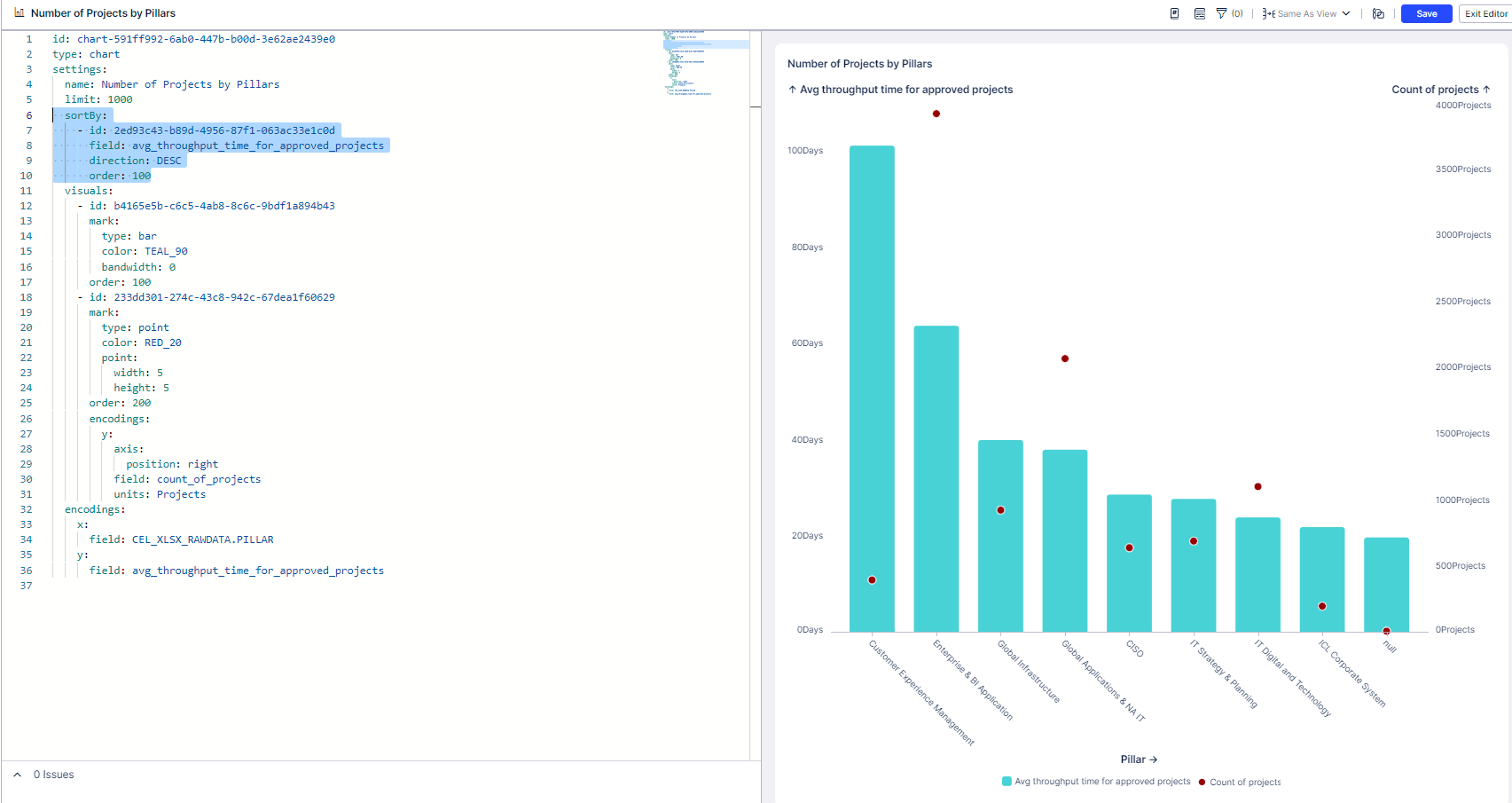
The weird thing here, is that when i'm changing the sorting statement on YAML editor to sort by the "count of projects" KPI, the numbers are good.
Happens only when sorting by the "Avg throughput time for approved projects" (Y axis PQL on the Bar chart layer - the first layer)
One thought is your result set greater than 1000 rows? If so, by sorting you are getting only the largest 1000 data points skewing upward rather than averaging an unsorted set.
Its not make sense to me due to the value of the "count of projects" KPI. there are 1996 projects overall, so I can't see how it is connects to the increase of values.
But thank you for you answer.