Simpler modeling for relationships for object-centric process mining (2024-02-08)
We've redesigned the Objects and Events user interface to give you more guidance when you're modeling custom object to object relationships and event to object relationships:
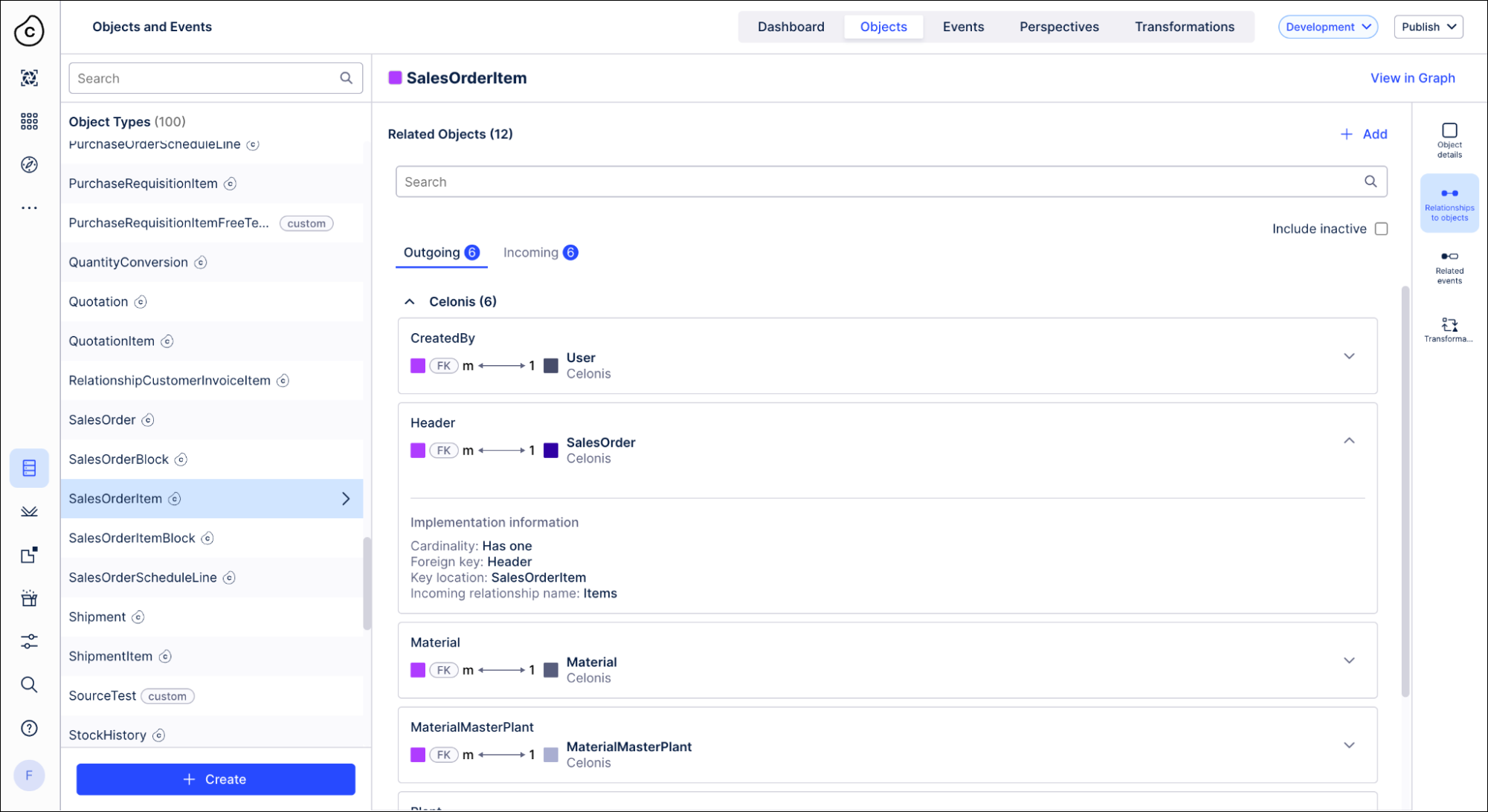
- The list of relationships for an object is now divided into outgoing relationships, where the foreign key or join table is to be implemented on this object, and incoming relationships, where the foreign key or join table is to be implemented on the other object. You can click any relationship to view the implementation details and the location of the transformation. You can also show inactive relationships that the object has for processes that you haven’t enabled yet.
- When you create a relationship between two object types, we now automatically create the relationship in the other direction as well. If you don't want a bidirectional relationship, you can delete it.
- We've combined the options for the relationship's cardinality with the choice of where and how to handle the relationship data in your transformations, so it's clearer what to choose and what you'll need to do afterwards.
Your choices for the cardinality of a custom relationship are now many to one (m:1), one to many (1:m), many to many (m:n) with the relationship table as a join table on the source object, or many to many (m:n) with a join table on the target object. We've removed the choice of a one to one (1:1) relationship, as the object-centric data model and the underlying database don't enforce uniqueness of a foreign key. Any custom one to one relationships already in your object types will continue to exist.
For the modeling documentation, see Modeling objects and events.