
Dear Celopeers,
I would like to save the third largest Count of Order Items per country as a variable.
E.g.:
DE - 7000
EN - 12000
IT - 9500
...
Variable: 7000
I only have access to these functions: https://help.celonis.de/display/PQL47/PQL+Function+Library+-+CPM+4.7
Thank you in advance!

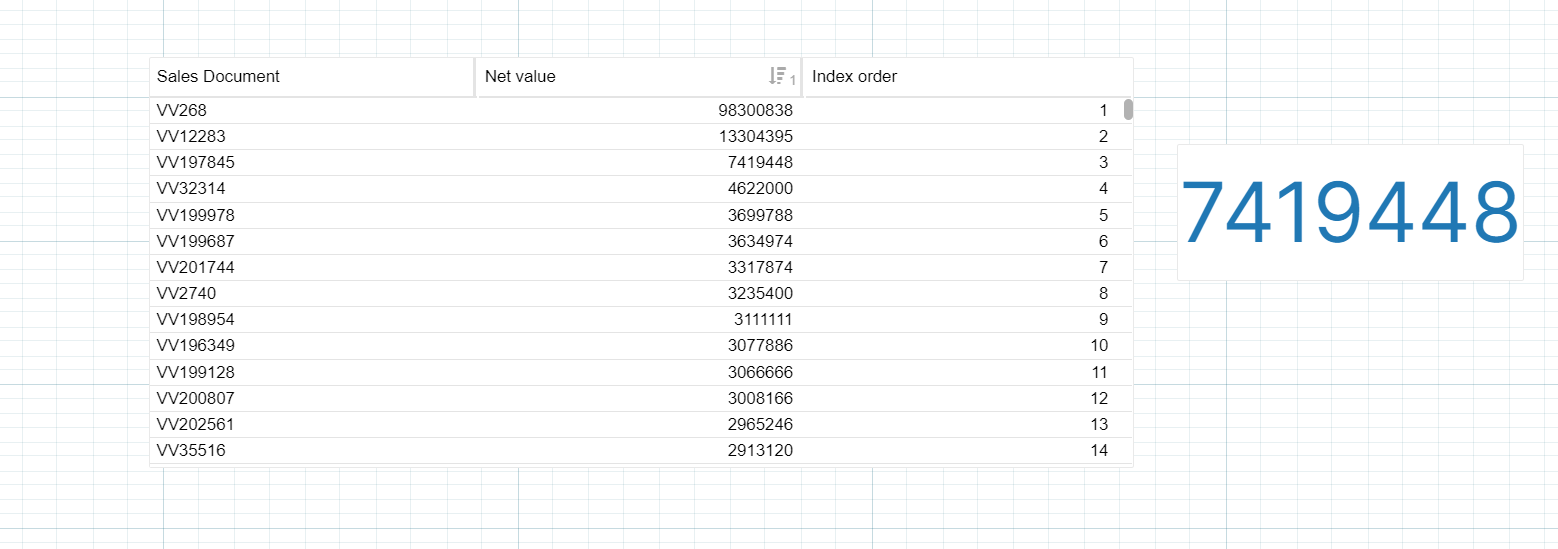 The OLAP table has two columns
The OLAP table has two columns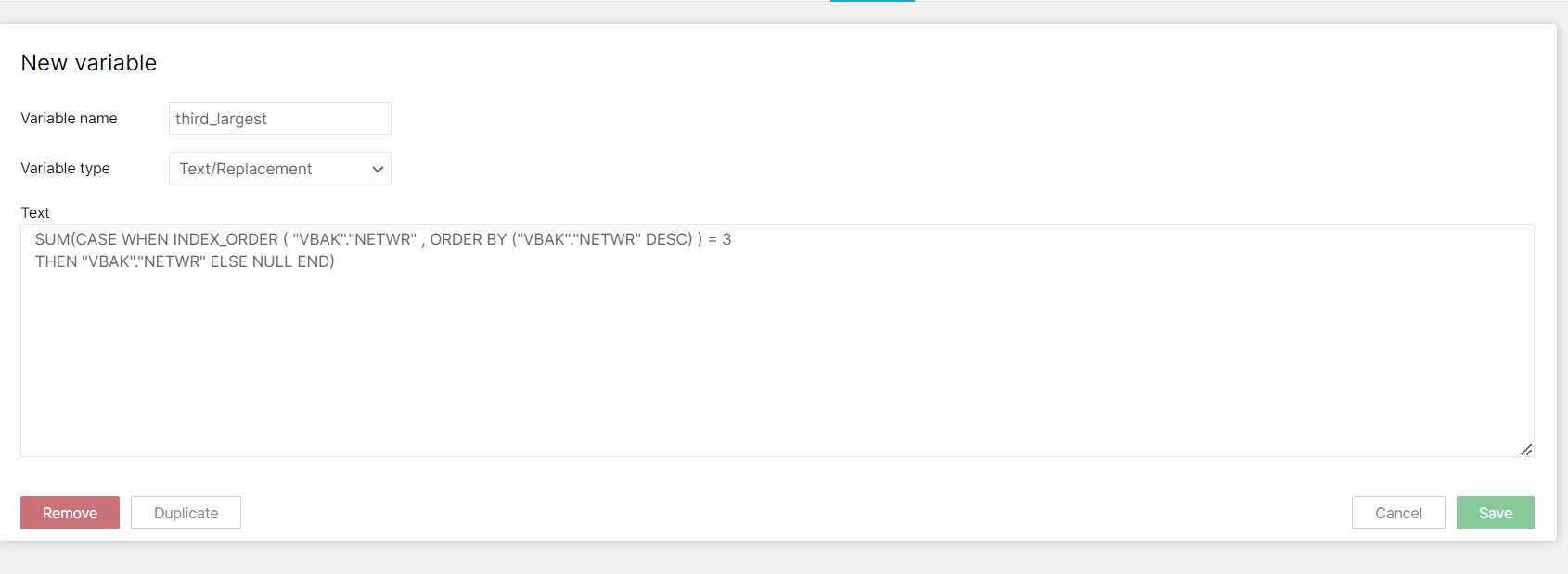
 Index Order - INDEX_ORDER ( "VBAK"."NETWR" ,ORDER BY ("VBAK"."NETWR" DESC),
Index Order - INDEX_ORDER ( "VBAK"."NETWR" ,ORDER BY ("VBAK"."NETWR" DESC),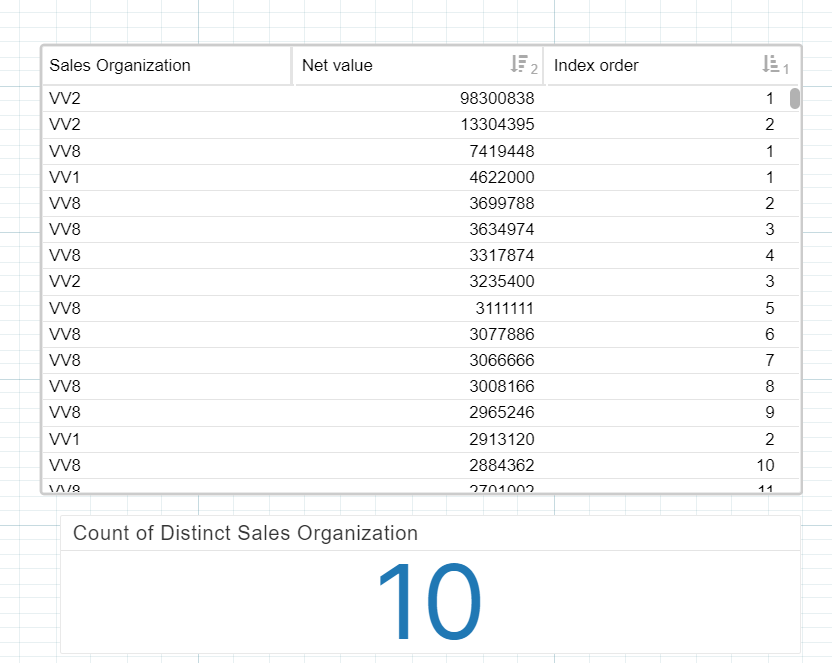 Index Order - INDEX_ORDER ( "VBAK"."NETWR" ,ORDER BY ("VBAK"."NETWR" DESC),
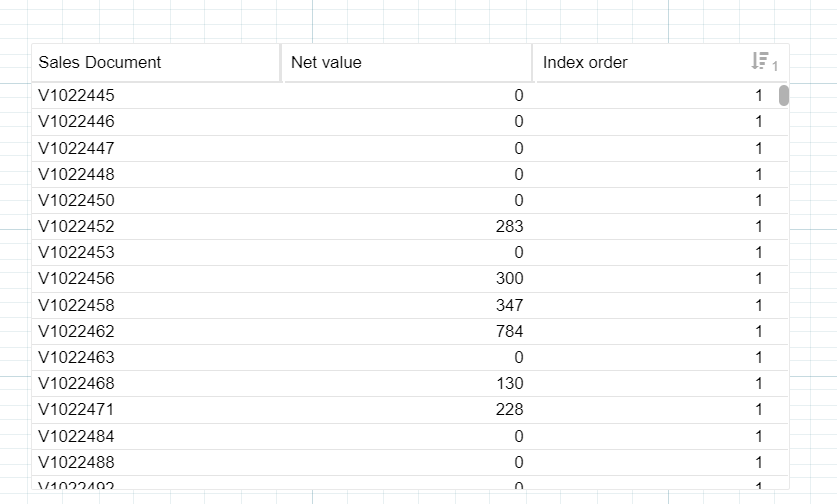
Index Order - INDEX_ORDER ( "VBAK"."NETWR" ,ORDER BY ("VBAK"."NETWR" DESC),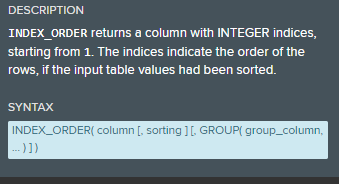 I always translated your functions into this format, but is it possible that 'GROUP' and PARTITION_BY' are not equivalent arguments...
I always translated your functions into this format, but is it possible that 'GROUP' and PARTITION_BY' are not equivalent arguments...