
The premise is in regards to the process explorer and its behavior when applying different levels of filters:
- applying process-related filters (flows through, select cases going from A to B) everything works as expected.
- Applying attribute selections on an activity level, i.e. selecting all activities performed by a single department, process explorer returns all cases where at least one activity within that case abides by the selected filter.
Thus it appears that the behavior of the process explorer is as follows:
- First find all activities that meet the defined condition
- Select all cases that belong to those activities
- visualize all activities for those cases in the process explorer without filtering the activities that do not meet the criteria.
What makes this matter more complex is the following:
- Standard Process Explorer KPIs (case count, activity count) are calculated based on the latter conditions. So all information of the case and all activities regardless of activity attribute conditions.
- Whereas custom Process Explorer KPIs (i.e. activities per case) are calculated based on the applied conditions or filter. Thus they look at a different activity table to calculate the KPI compared to the standard process explorer KPIs. Especially for a KPI like activities per case this difference is hard to explain as it is also a standard KPI provided when selecting an activity. For an example see the attached image: 1.3 is the calculated KPI based on the applied filters, whereas the 2.2 times per case is the calculated KPI if those filters are ignored.
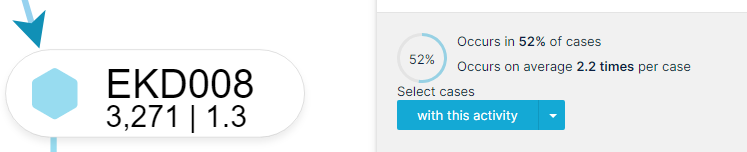
I'm struggling to explain this behavior to my colleagues. I think the main reason is that the process explorer always tries to provide the full picture and will not crop the process due to selections on an activity level.
What are your thoughts on this?

