


Problem: In the dataset I am working with, a mistaken batch process in the source system added extra timestamps which are throwing off throughput times.
Objective: My objective is to map to null all activities in my activity table which are repeated back to back.
Example: In the simplified table below, I would want the final activity to map to null since it is a repeated activity "c" of the same work order "3"
Table = "Celonis_Remap_Practice_csv"
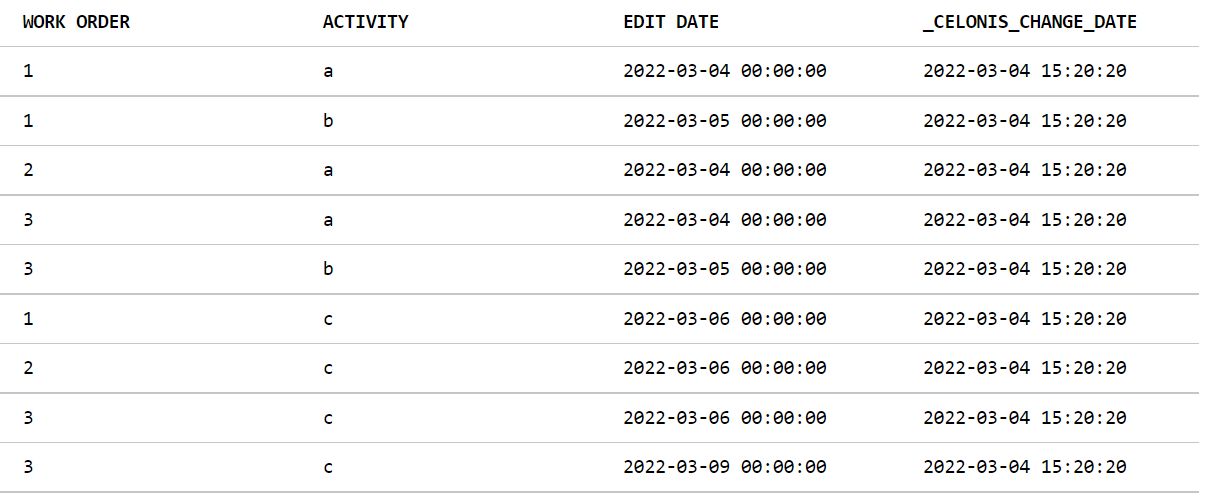
Partial Solution:
I created a custom dimension on a variant explorer with the following code:
CASE
WHEN
"Celonis_Remap_Practice_csv"."Activity" = ACTIVITY_LAG ("Celonis_Remap_Practice_csv"."ACTIVITY")
AND INDEX_ACTIVITY_ORDER ( "Celonis_Remap_Practice_csv"."ACTIVITY" ) > 1
THEN NULL
ELSE "Celonis_Remap_Practice_csv"."Activity"
END;
This effectively removed the duplicate activity from the variant explorer, but I want duplicate activities completely removed from the analysis.
Question 1: How can I create an analysis level filter that removes duplicate activities without removing entire cases with duplicate activities?
-or-
Question 2: How can I write a valid "WHERE" statement in a data transformation in Event Collection given that functions such as Activity_Lag and Index_Activity_Order are not supported?
-- This is what I have tried so far
UPDATE "Celonis_Remap_Practice_csv"
SET "Activity" = NULL
WHERE "Celonis_Remap_Practice_csv"."Activity" = ACTIVITY_LAG ("Celonis_Remap_Practice_csv"."ACTIVITY")
AND INDEX_ACTIVITY_ORDER("Celonis_Remap_Practice_csv"."Activity") > 1;
