
Question
Feature request: Allow multiple case/activity notions within the same data model
 +9
+9We have connected Celonis to our central data core. This means we have data of over 700 processes in one generic table structure (case, step, process, client, etc.). However, this also means that if we want to have different case notions (for instance one analysis has a process as scope and hence case=case, while another is focusing on customer journey where case=client). Currently this means we have to load in the data twice (or more), with different activity/case notions set. This means duplication of the data. It would be nice if this setting could be data model independent (or: one data model has several case/act notions from which the dashboard can select one).
Im aware of the process explorer option to change the activity attribute, but my request/suggestion is also concerning the case notion.
 Thanks a lot,
Max
Thanks a lot,
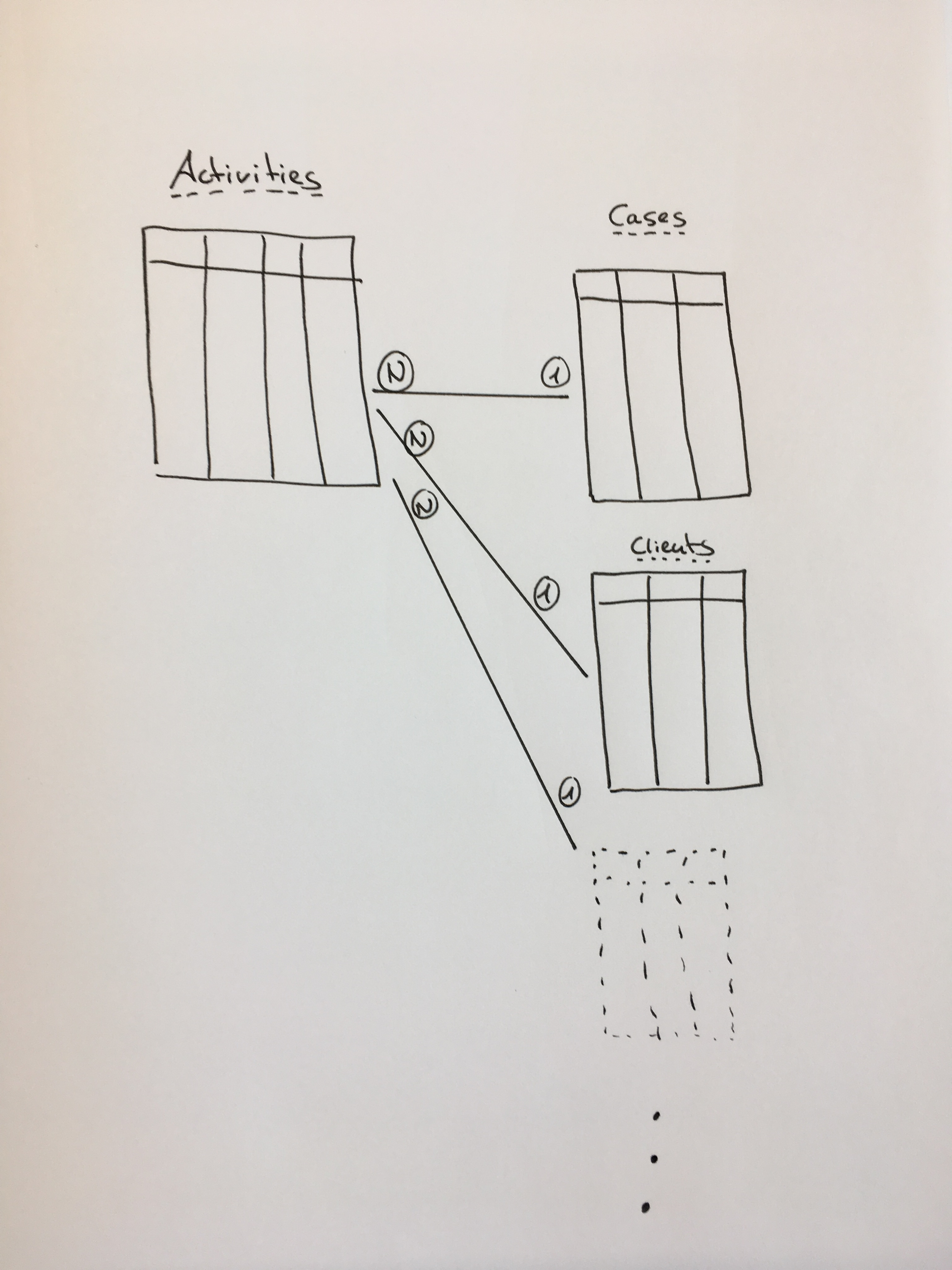
Max The situation is a bit different. We have generic tables for client, case, process, process step, etc.
A case can run over several processes, even for multiple clients.
The data consists of 30+ million cases and already over 107 million events (process step in our terminology).
The issue/request is that sometimes we have client as case notion (which processes ran for a client), and sometimes case (which processes and steps were executed for a specific case instance).
Having the datamodel loaded and defined twice would be a waste in my opinion. Hence: would it be possible to have views (case & activity definitions) on the same underlying table structure?
See the picture below for our situation: we combine data from several (and increasingly more) systems into a generic company-wide data structure, where Celonis connects to the generic process part of the database.
image.png1089677 41.8 KB
I hope this clarifies it a little bit. If you have any further questions please let me know.
The situation is a bit different. We have generic tables for client, case, process, process step, etc.
A case can run over several processes, even for multiple clients.
The data consists of 30+ million cases and already over 107 million events (process step in our terminology).
The issue/request is that sometimes we have client as case notion (which processes ran for a client), and sometimes case (which processes and steps were executed for a specific case instance).
Having the datamodel loaded and defined twice would be a waste in my opinion. Hence: would it be possible to have views (case & activity definitions) on the same underlying table structure?
See the picture below for our situation: we combine data from several (and increasingly more) systems into a generic company-wide data structure, where Celonis connects to the generic process part of the database.
image.png1089677 41.8 KB
I hope this clarifies it a little bit. If you have any further questions please let me know.Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.