

Hi @all,
We have a Data Pool with 2 Data Models: Data Model “ECI Data Model HTD - TABLES - TEST” has been duplicated from the Data Model “ECI Data Model HTD - TABLES”.
If we do a “Manual - Complete Reload” of both Data Pools, the load times are very differents:
- “ECI Data Model HTD – TABLES” --> 34 min

- “ECI Data Model HTD – TABLES – TEST” --> 21 min

Apparently, the load time of each of the tables is very similar:
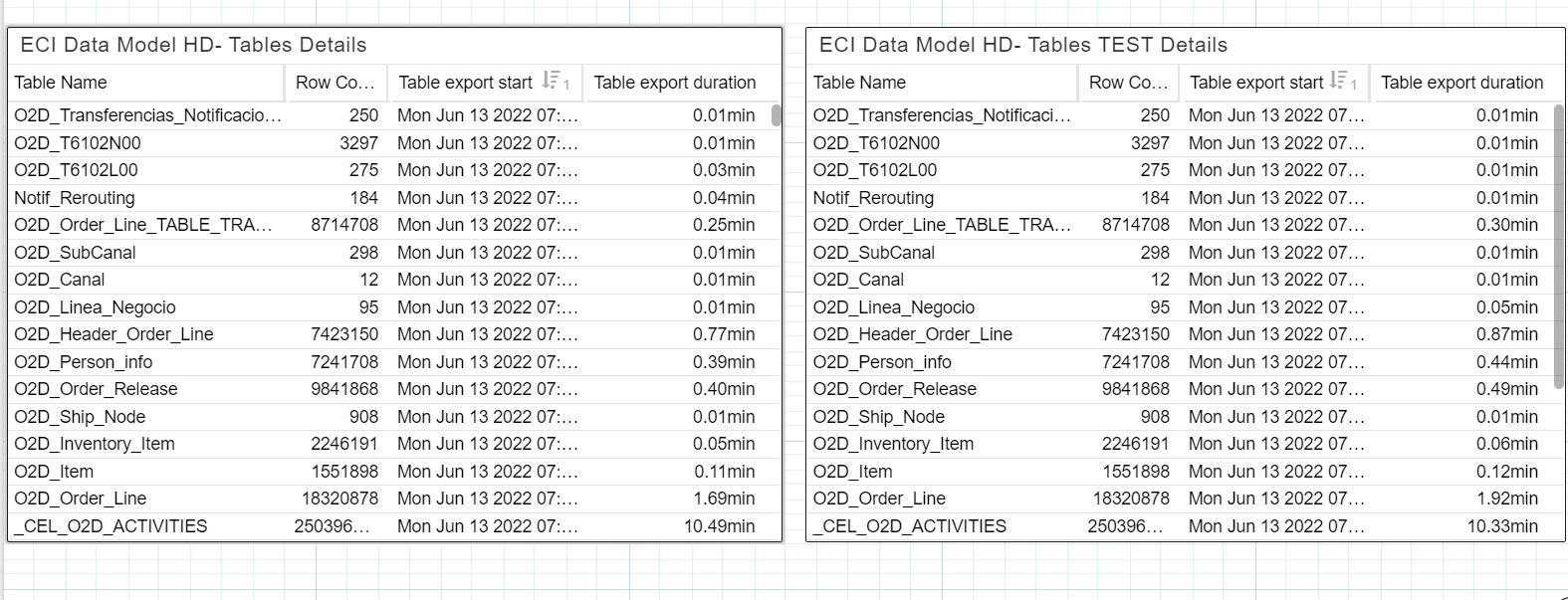
If we do a "Manual - Partial Reload" on both Data Pools of a table that only contains 87 records, the load times are also very differents:
- “ECI Data Model HTD – TABLES” --> 19 min

- “ECI Data Model HTD – TABLES – TEST” --> 3 min

What could be due to these differences? As we said before, the Data Model that has the best times has been duplicated from the previous one.
Thanks in advance!

 5. When I run a Complete load of Data Model "B", it takes 19 min.
5. When I run a Complete load of Data Model "B", it takes 19 min.
