First, the SQL for that is:
"select table_name, column_name, data_type, data_type_length from columns where table_name like <table_name> "
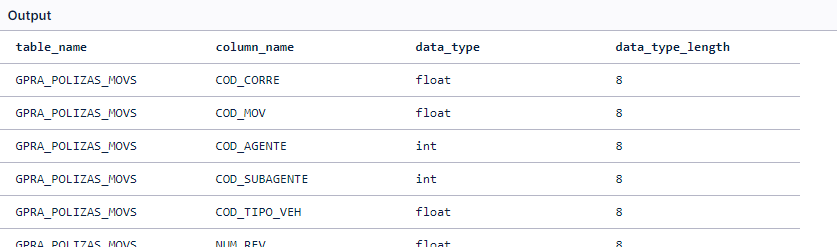
Caveat: it will not work for views.
Second, with PYCelonis you can iterate all the tables of the datapool, then execute the SQL above changing the table name. The output is a dataframe (I think)
New caveat: when you execute a SQL, it will return only 100 lines. For your case use I guess will not be a problem, but... well, shit happens and you can have a table with more than 100 columns
Workaround: use python to create a SQL script that will create a new table, then inserting into it all the output of the columns details of all the tables. Execute the script from the Data Integration. Add the resultant table into a Process Model and either consume it from Celonis Studio, or from python retrieve all the lines using pycelonis.pql -- from pycelonis.pql import PQL, PQLColumn --- the result will be a dataframe that you can export to excel or csv or your preferred format.
Alternative: you can use Data Explorer, although is more "interactive" and I guess what you want is to document quickly all the struct in your data pool
HTH
