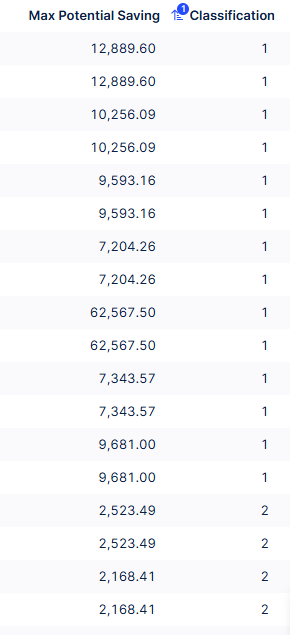
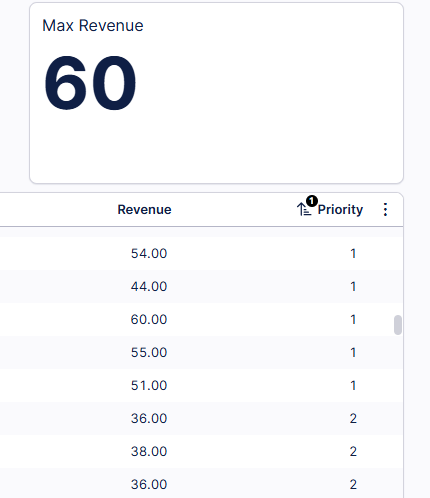
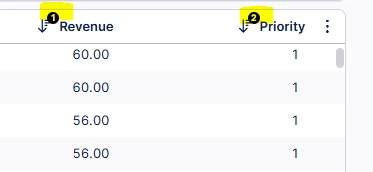
Hi everyone,
I have a column with many numbers, and I have uploaded a screenshot as an example. I want to classify them into groups. FYI: I know the maximum, minimum, and median, and I also know the total number of numbers.
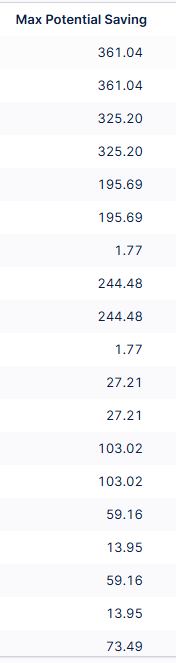
How can I do that?
Thanks in advance!