

Hi!
I have a use case when a specific field within 1 case can be changed multiple times during the case lifecycle (e.g. fields containing metadata around the Vacancy case). The aim is to figure out what is the influence of specific field changes on the Vacancy throughput time. For this, I am using range buckets calculated based on the number of specific field changes per Vacancy.
I've created 2 tables with buckets: the first table allocates a Vacancy to a range bucket (OLAP table dimension) using PU_COUNT function and the second table does the same using CALC_REWORK function (all formulas are provided below). Then I calculated the # of vacancies in each bucket and the average # of field changes in a bucket (both tables show the same result). Then I am adding throughput time calculation to the tables, and the result is the same at a first glance. But when I hide the column with average # of field changes in a bucket from the second table, throughput time is recalculated. Please, see the attached gif.
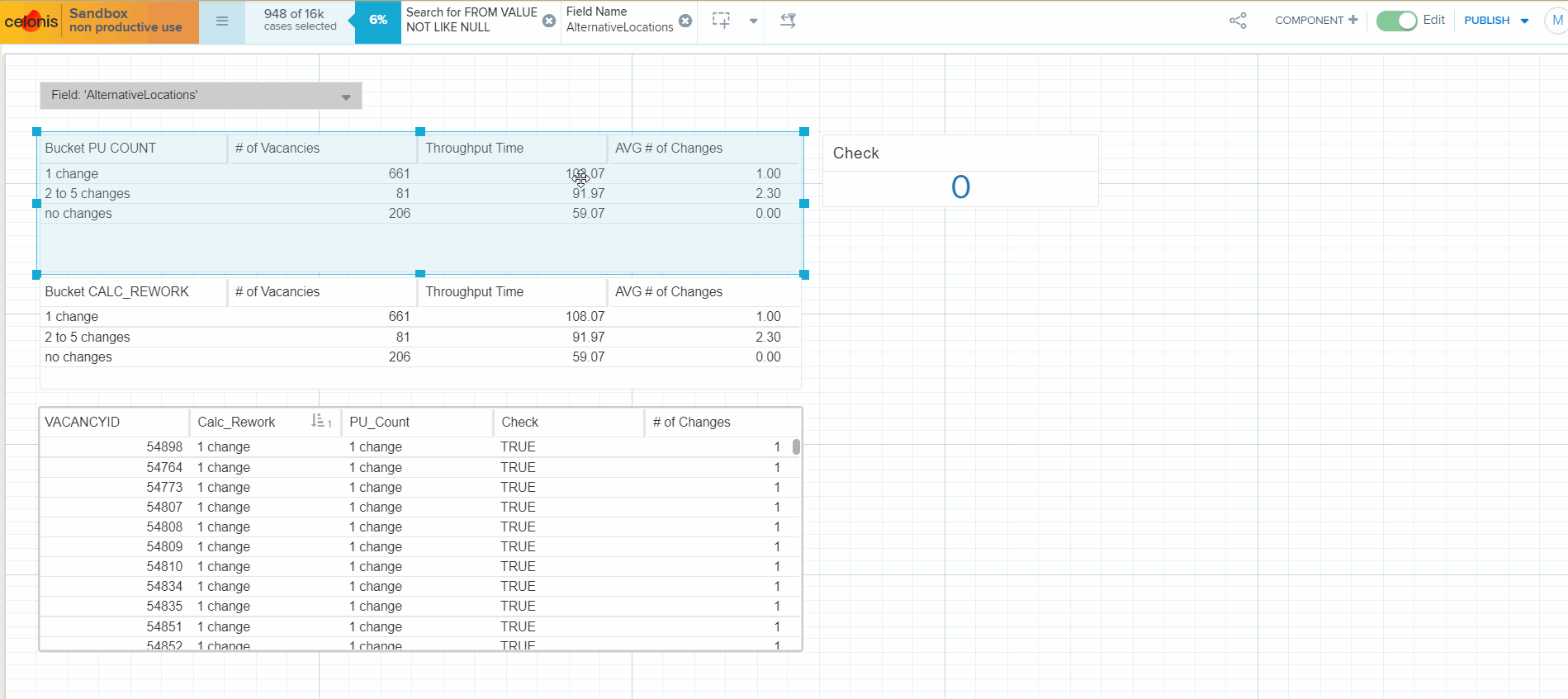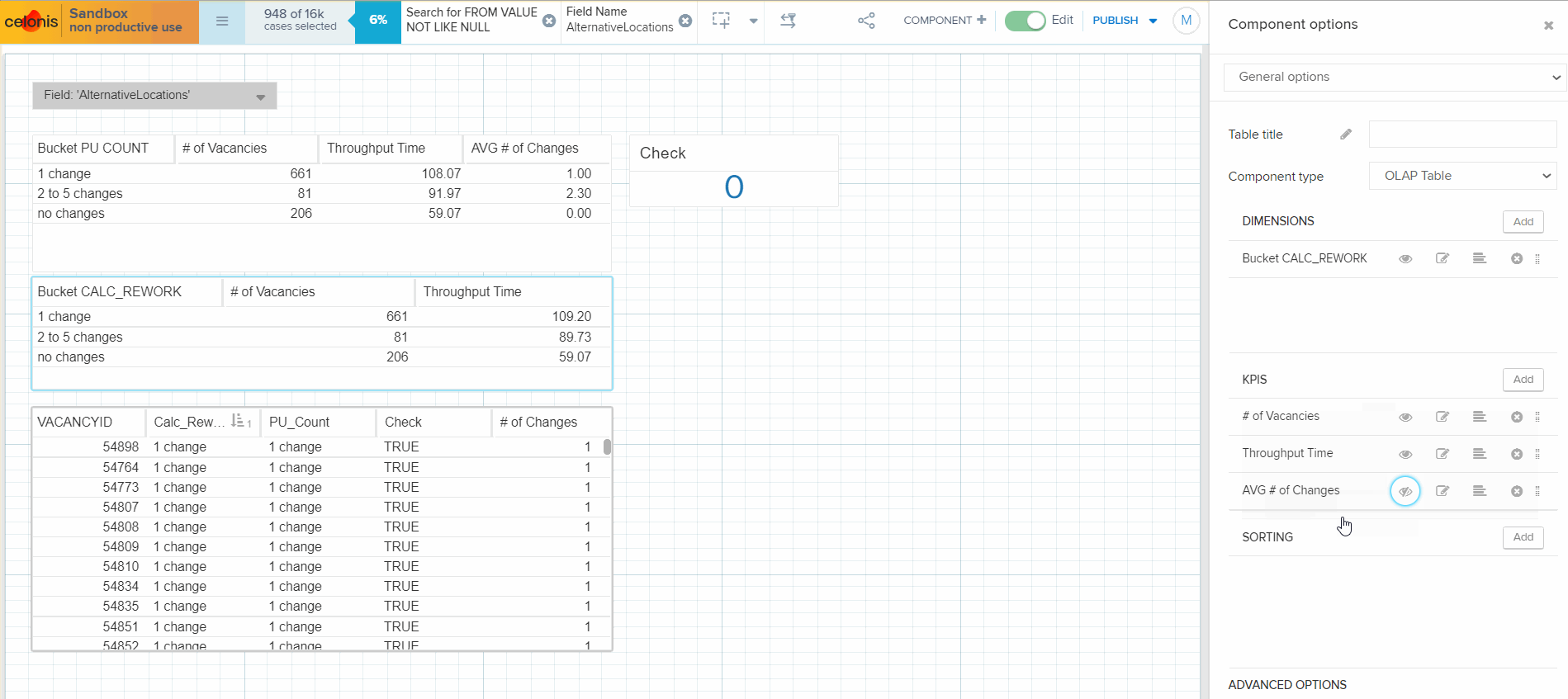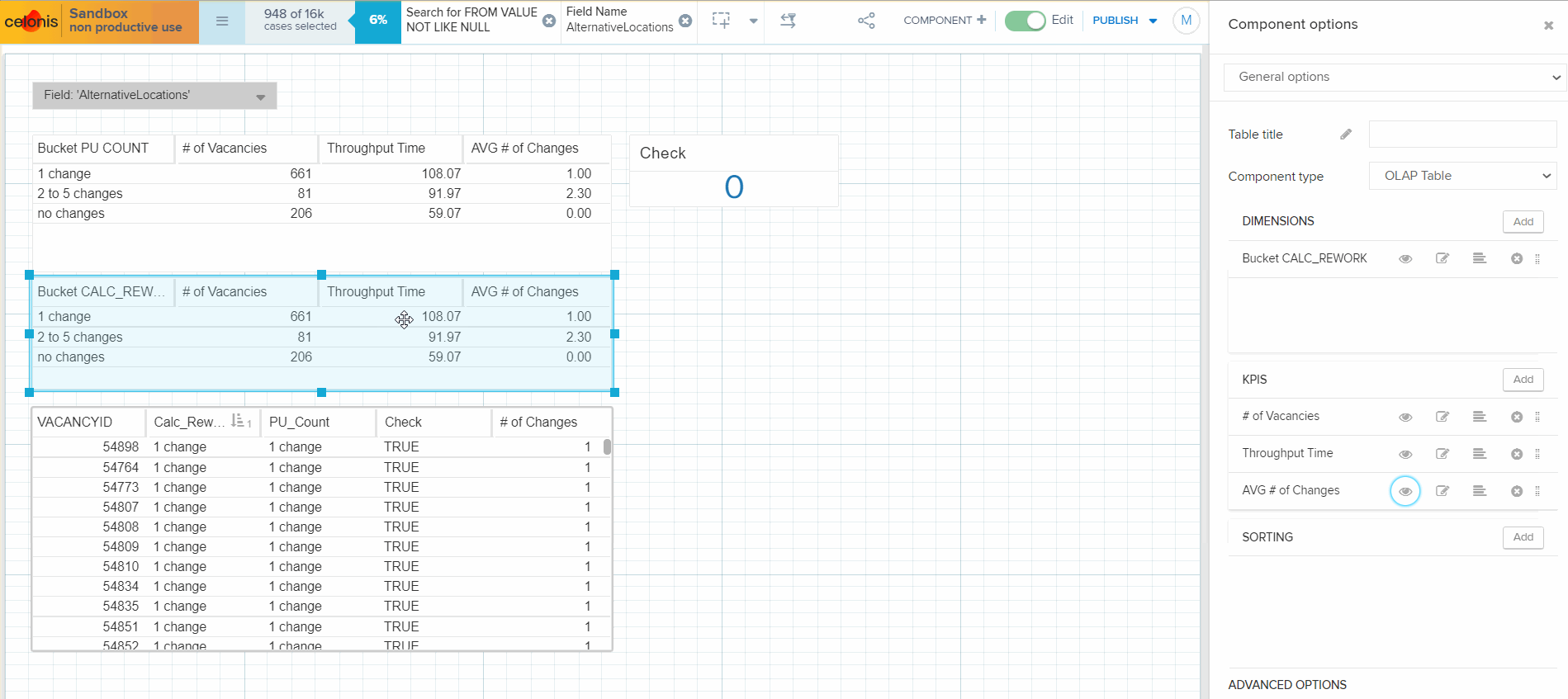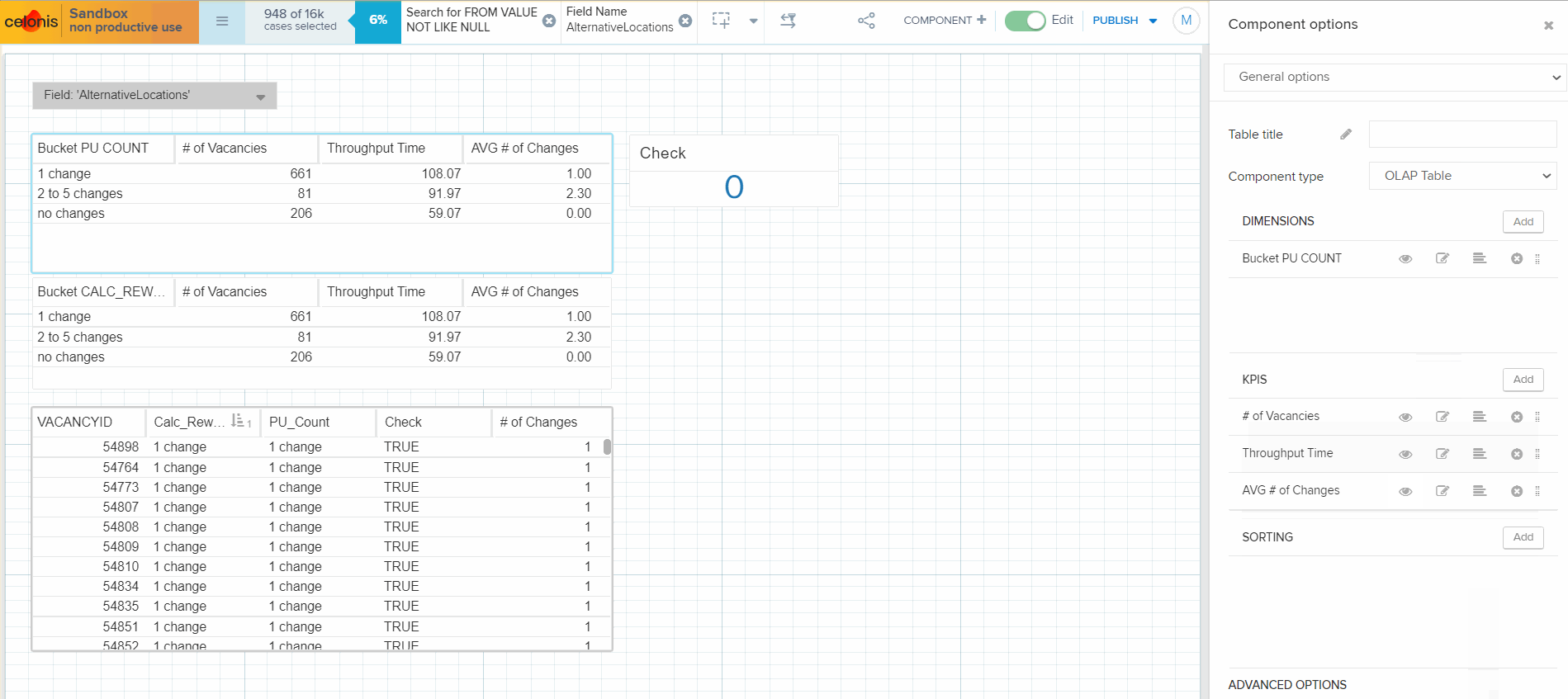 Could you please help me to figure out why the throughput time calculation is different between the tables? The expectation is that both tables must calculate the same values, as there is no difference in the formula used for throughput calculation.
Could you please help me to figure out why the throughput time calculation is different between the tables? The expectation is that both tables must calculate the same values, as there is no difference in the formula used for throughput calculation.
Formulas used:
Bucket with PU_COUNT:
CASE
WHEN PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') =0
THEN 'no changes'
WHEN PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') = 1
THEN '1 change'
WHEN PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') > 1
AND PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') <= 5
THEN '2 to 5 changes'
WHEN PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') > 5
AND PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') <= 10
THEN '6 to 10 changes'
WHEN PU_COUNT ("GTO_Vacancy_Current_State_csv", "GTO_Vacancy_Workflow_csv"."FIELD",
"GTO_Vacancy_Workflow_csv"."FIELD" IN (<%=With_field%>) AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') > 10
THEN 'more than 10 changes'
END
Bucket with CALC_REWORK:
CASE
WHEN CALC_REWORK ("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') =0
THEN 'no changes'
WHEN CALC_REWORK ("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') = 1
THEN '1 change'
WHEN CALC_REWORK ("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') > 1
AND CALC_REWORK ("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') <= 5
THEN '2 to 5 changes'
WHEN CALC_REWORK("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') > 5
AND CALC_REWORK("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') <= 10
THEN '6 to 10 changes'
WHEN CALC_REWORK("GTO_Vacancy_Workflow_csv"."FIELD"= <%=With_field%> AND "GTO_Vacancy_Workflow_csv"."FROM VALUE" != 'NULL') > 10
THEN 'more than 10 changes'
END
Throughput time:
TRIMMED_MEAN(CALC_THROUGHPUT(CASE_START TO CASE_END, REMAP_TIMESTAMPS("GTO_Vacancy_Workflow_csv"."CHANGE DATE", DAYS)), 5, 5)
