
Good morning,
I know the title is a bit convoluted, but I will provide additional information here.
Essentially, we are trying to build a Bar Chart, with 1 Dimension and 1 KPI:
Dimension: Purchasing Document Item Creation Month
KPI: % of Distinctly Named Suppliers that have at least 1 Purchasing Document Item with certain characteristics:
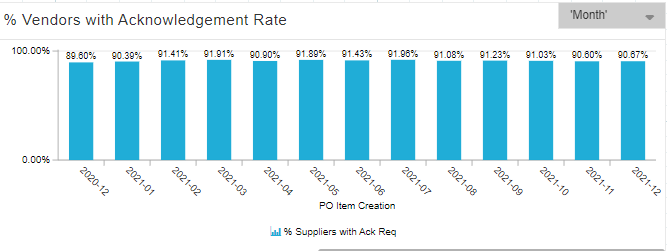 This is what it currently looks like, without any filters.
This is what it currently looks like, without any filters.
However, it does not effectively evaluate each supplier, each month.
It evaluates each supplier across the entire data pool.
Example:
Supplier #1 Selected:
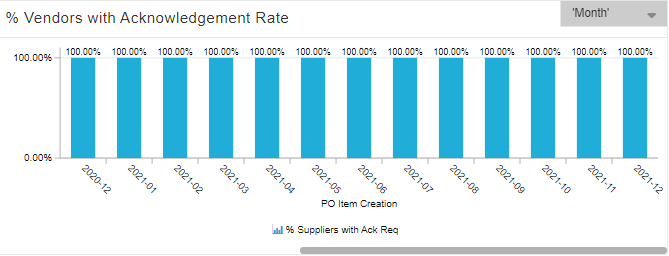 Great performance right? 100% Across the board!
Great performance right? 100% Across the board!
Now, if I look at the actual data, through some non-clustering formulas (no use of PU_SUM, PU_COUNT, etc.):
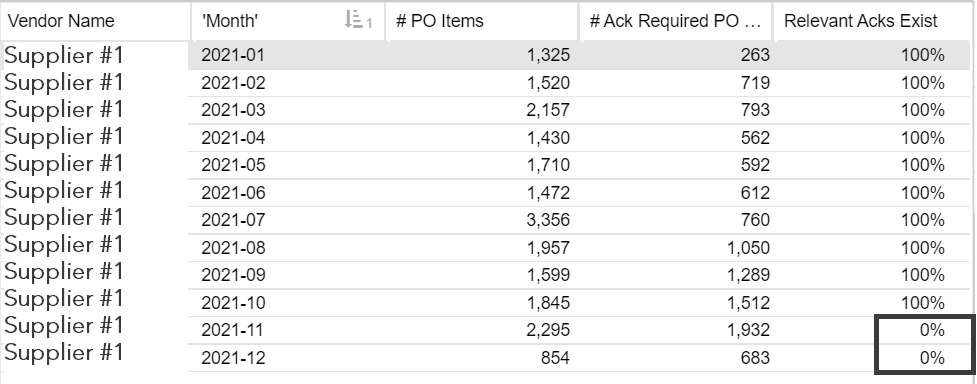
As you can see, this supplier actually had no Purchasing Document Items within the defined characteristics (Acknowledgement) for the months of November and December 2021, however, looking back at the graph:

100% for both months..
To summarize, the formula is:
- Looking at each distinct Supplier Name
- Checking if at least 1 Purchasing Document Item exists within the defined characteristics
- If it does (regardless of the month it's in), it sets the Supplier Name at 100%
- Averages all Supplier Name scores, for Supplier Names with Purchasing Document Items created that month
Whereas we would like the formula to:
- Look at each distinct Supplier Name
- Check if, in the pool of a Purchasing Document Item's Creation Month, at least 1 Purchasing Document Item (For that same Supplier Name) exists within the defined characteristics
- If it does, it sets the Supplier Name at 100%
- Average all Supplier Name scores for that month
Here is the formula we are currently using:
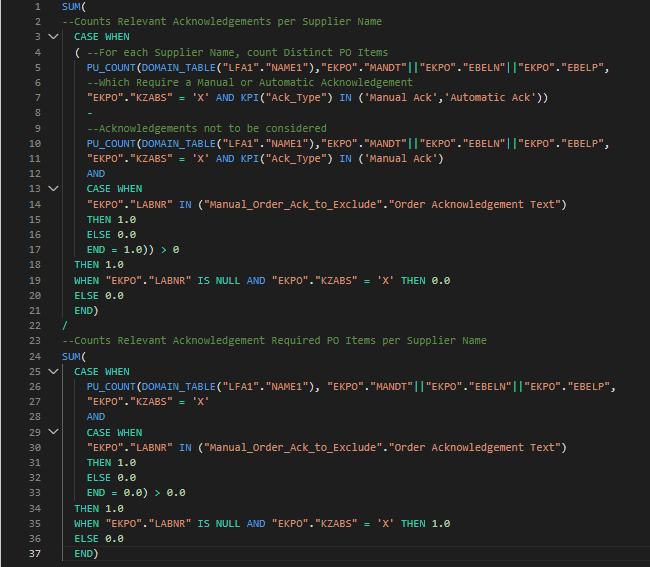
Apologies for the long post, I'm not sure if there are any other formulas we could be using, any help would be much appreciated.
P.S: You can find the actual PQL text in the comments
Thank you very much!!